






.webp)





Ever since generative AI and LLMs took center stage in the world, workers have been wondering how best to apply these transformative new tools to their workflows. However, many of them ran into similar problems while trying to integrate generative AI into enterprise environments, like privacy breaches, lack of relevance, and a need for better personalization in the results they received.
To address this, most have concluded that the answer lies in retrieval augmented generation (RAG). RAG separates knowledge retrieval from the generation process via external discovery systems like enterprise search. This enables LLMs and the responses they provide to be grounded in real, external enterprise knowledge that can be readily surfaced, traced, and referenced.
Vector or lexical search alone isn’t enough
Now that enterprises understand that generative AI solutions require a separate retrieval solution, many ask—why don’t we just put our content into a vector database and implement a simple RAG prompt? The answer unfortunately isn’t so simple, particularly when it comes to delivering a truly enterprise-ready experience.
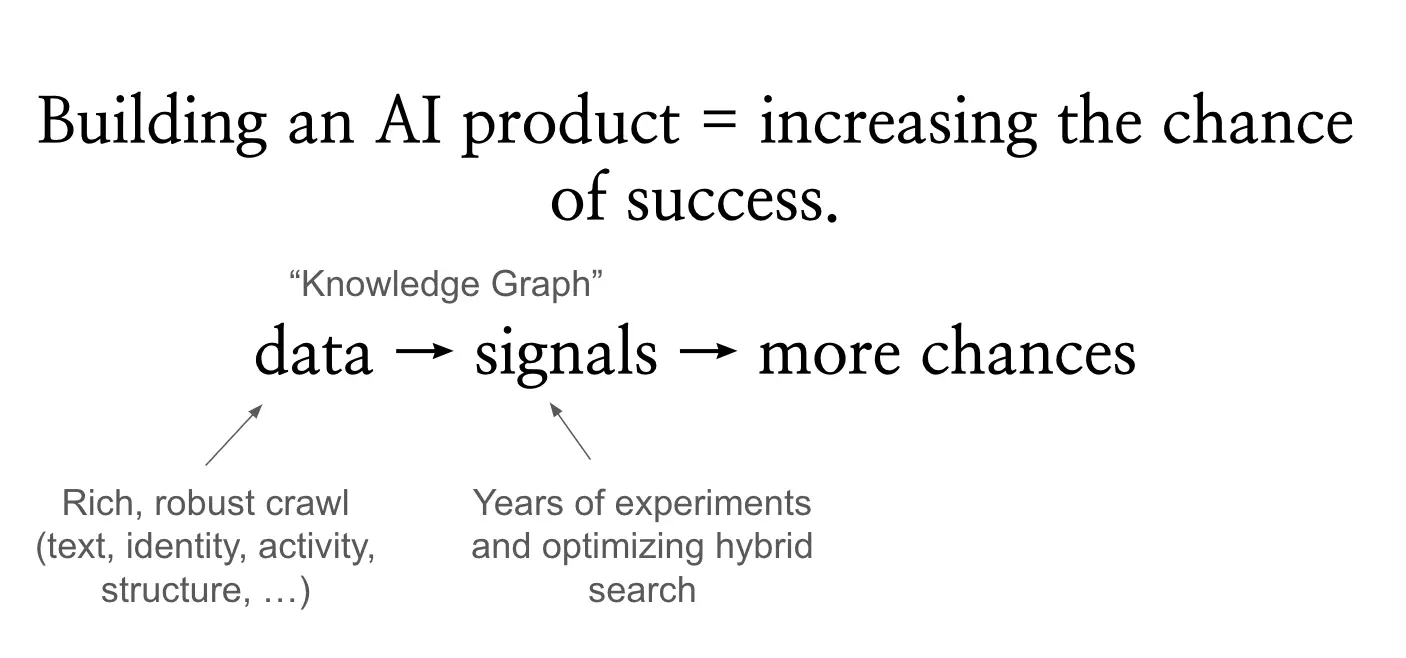
Let’s briefly explore how vector search and databases work for data indexing and retrieval. Embedding models effectively map specific text to a fixed vector of numbers—given a set of words, the model will assign a numerical value that represents it within the database. Then, given a query's text, the system can compute how 'close' the text in the query is to pre-indexed document texts in that vector space, which it then pulls to display in the results.
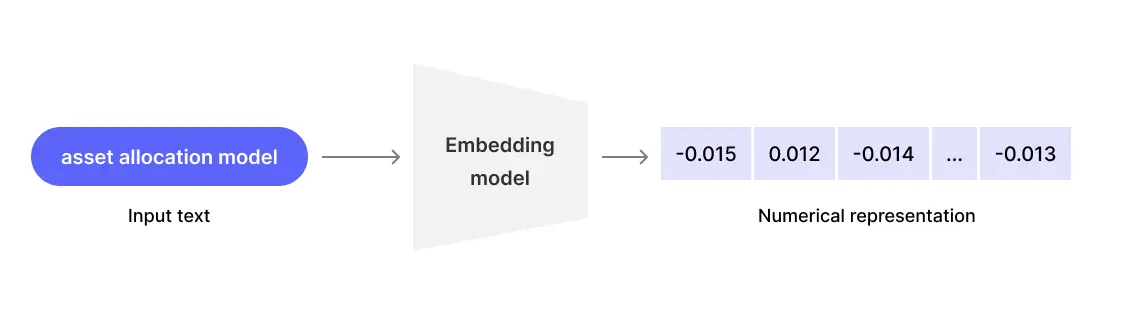
This step should simply serve as the information retrieval process. LLMs are then strictly used as a reasoning layer to initially call the search/retrieval engine, read limited context, then distill and generate coherent responses given the right information via the vector database.
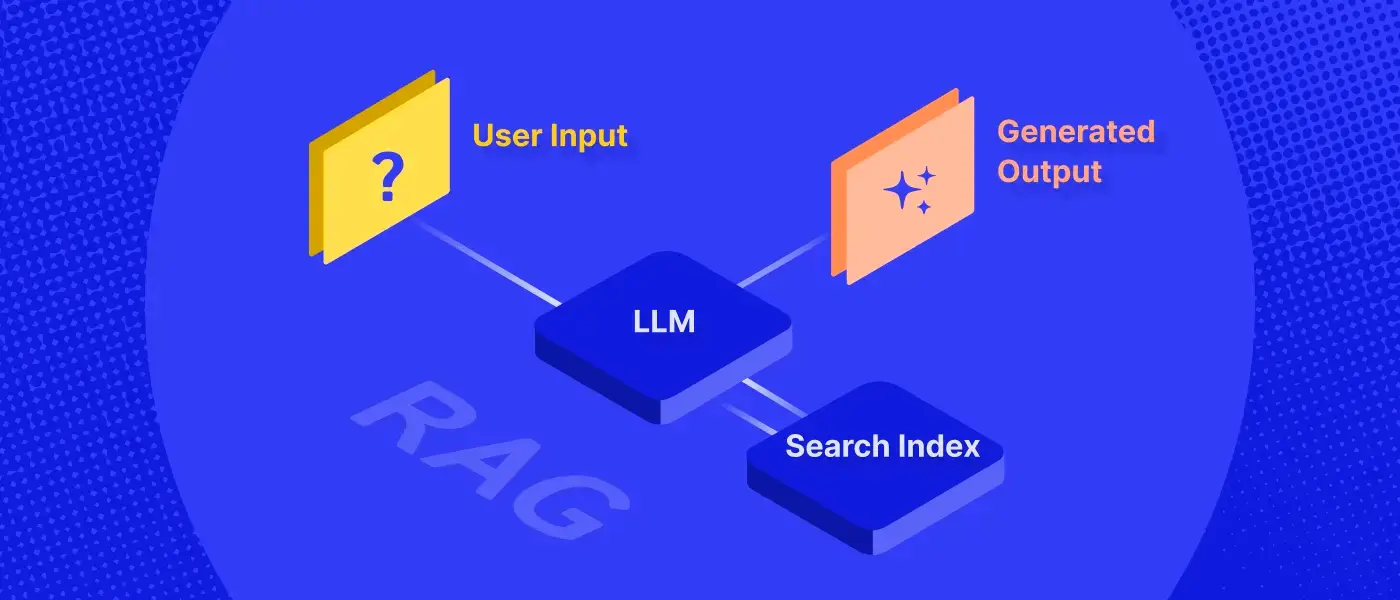
Although improvements in vector search signal a fundamental shift in semantic understanding, it’s a small piece of the puzzle in delivering high-quality results for enterprise search. Alone, simple vector search is incapable of recognizing the more complex connections between all the content, people, and activity within an organization.
Even more dated are simple lexical search systems, which instead match query terms directly against document content and metadata terms. Although easy to implement, they’re only capable of utilizing exact matches of words or phrases in a database, which poses serious limitations—particularly in the face of human errors when providing queries.
Improved results with hybrid search
Instead, solutions utilizing a hybrid search system can deliver the best of all worlds. For example, Glean’s complex RAG solution features four core technical differentiators that sets its hybrid search and generative AI solution apart:
- Knowledge graph framework for all enterprise data, with proprietary anchors and signals that powers search
- Rich, robust, scalable crawler connecting to all enterprise data and permissioning rules
- Levels for controlling and optimizing the LLM to Glean’s search interface
- End-to-end user experience optimization
Central to Glean’s robust results is the knowledge graph—a network of countless signals and anchors that all work towards addressing problems a potential builder has to solve. These factors help Glean acquire the rich context behind all the documents, people, and activity within an organization, helping better inform models about the information they need to deliver great results. Put simply, signals and anchors are like the clues you need to solve a mystery. The more a solution has to work with, the better the result will be!
For example, Glean’s signals are actively solving for individual search and personalization problems like:
- Normalization (tokenization, stemming, lemmatization)
- Synonymy (mining, contextual scoring, acronyms)
- Structured annotation (concept and entity mining and scoring)
- Internationalization
- Intent classification
- Document understanding (salient terms, topic modeling, handling templates, document classification)
- Retrieval and topicality (semantic search, term weighting, optionalization, term mixing, anchors, clickboost, hybrid optimization)
- Popularity (personalization, staleness/freshness, department modeling)
- Etc…
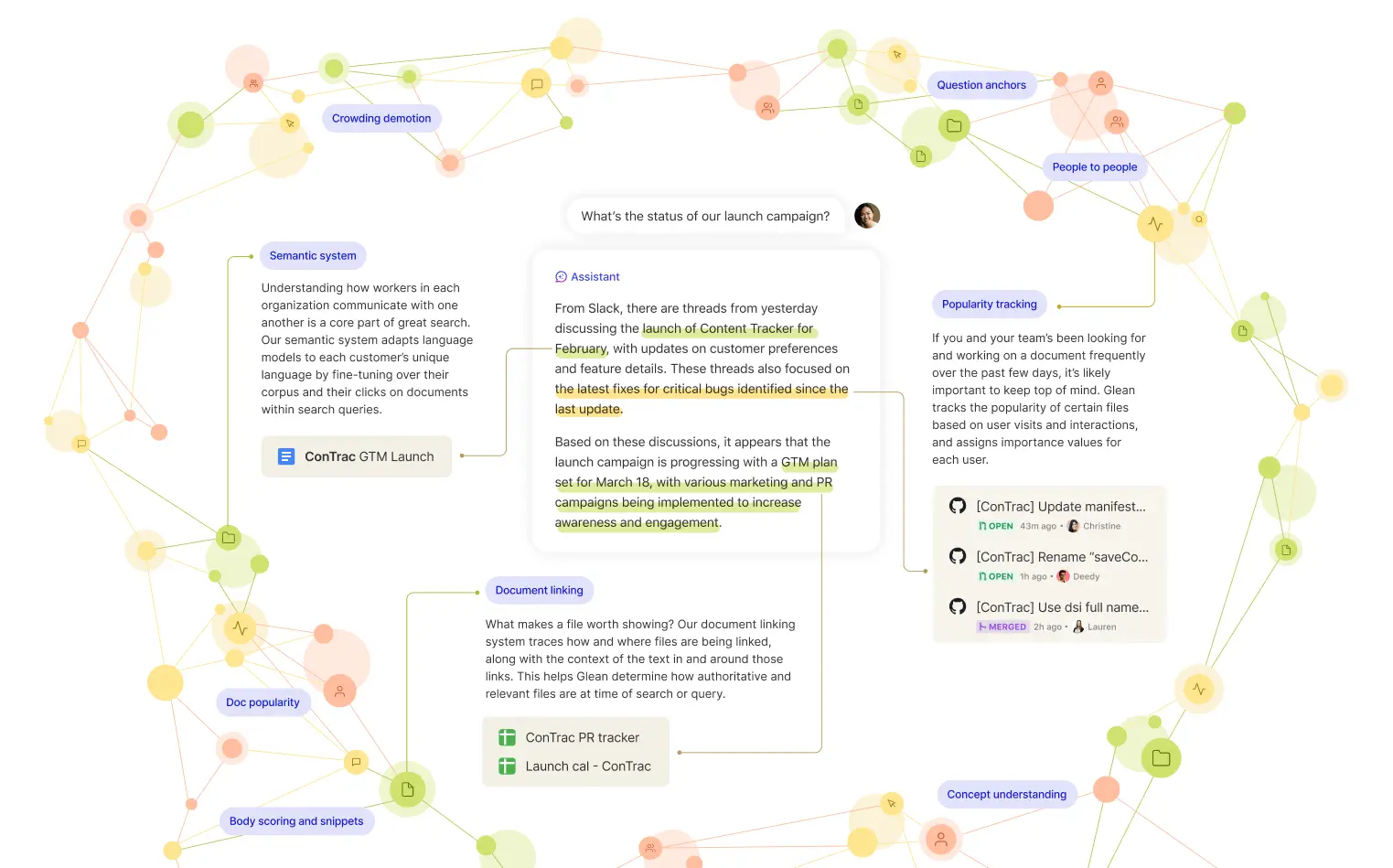
So what’s the noticeable difference between a system with a complex RAG solution, and one without? Let’s take a look at a quick example of some generated results.
Here at Glean, Scholastic serves as our approach to integrating semantic search into ranking stacks, focusing on retrieval and scoring based on titles, anchors, and headers. Let’s see what a standard RAG solution might reply in comparison to Glean when asked about Scholastic:
Standard (Vector, simple RAG)
Q: What is Scholastic?
A: Scholastic, located in New York City, New York, is a publisher and distributor of children's books, educational technology, and related services…
Glean (Hybrid, complex RAG)
Q: What is Scholastic?
A: Scholastic is our learned vector-based retrieval and scoring system (a play on our keyword-based system, Elastic). It learns item embeddings for documents and messages, and retrieves / scores nearest neighbors for a given query...
The standard response is completely irrelevant for a workplace query, while Glean’s response understands the assignment and provides exactly what the user is looking for.
Whether they’re responses delivered by generative AI, or results provided within a search, hybrid, complex RAG solutions augmented by networks of signals and anchors definitively deliver better results than incomplete lexical or vector search solutions. The capability of utilizing proprietary data as the keys and clues to fine-tuning models provides the rich contextualization that enterprise environments need from search and generative AI solutions.
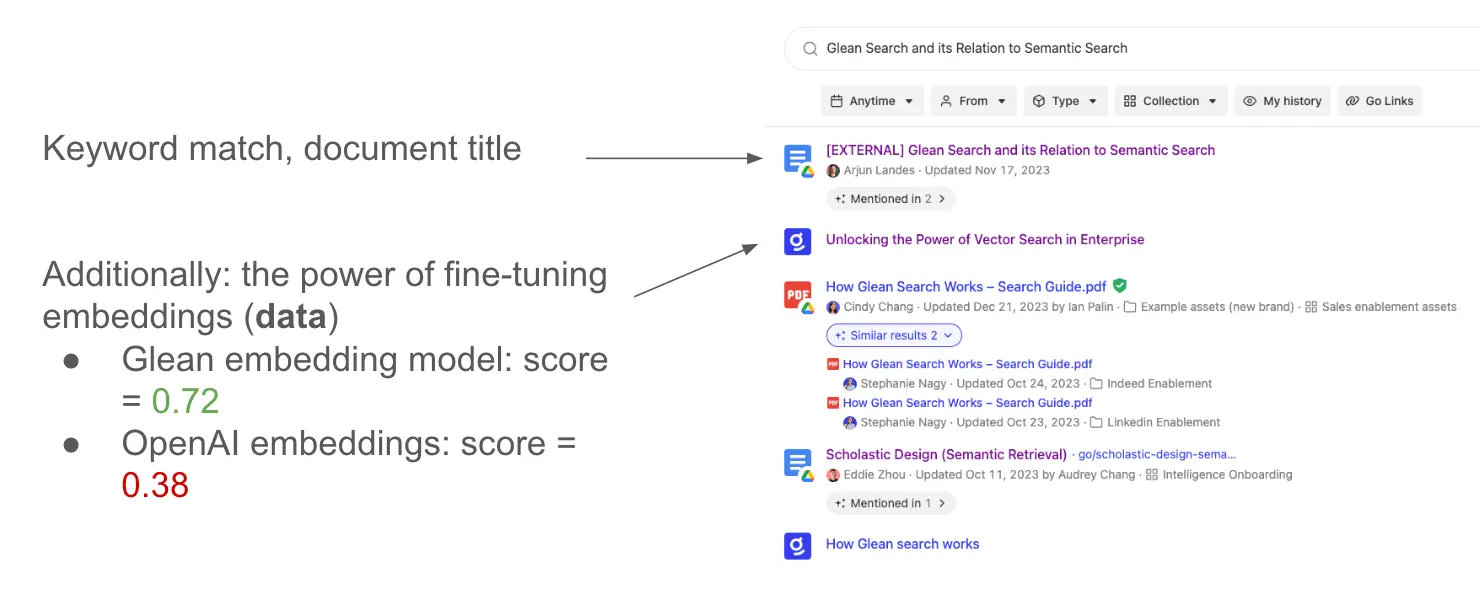
In the realm of enterprise search, it's also evident that relying solely on vector or semantic search may not always yield the most optimal results. This is particularly true in scenarios where there's a need for precision—such as when searching for specific terms, documents, or keywords. Vector search, with its inherent fuzziness, might not always align with the precision required in these instances.
For Glean, our lexical search capabilities also stand out due to the robustness of our data. This strength allows us to not only match queries with high accuracy but also to personalize results amidst a plethora of potential matches. The hybrid search approach that Glean employs marries the best of both worlds, leveraging the precision of lexical search and the nuanced understanding of vector search—all powered by the additional context and nuance provided by the signals and anchors within our knowledge graph.
To top it off, Glean’s capability of linking LLMs with our proprietary search interface enables us to handle search and retrieval misses much more gracefully. LLMs integrated with our search interface handle search and retrieval misses much more eloquently. For example, most third-party solutions, when faced with a question they cannot adequately answer, often provide poor information that isn’t fresh or relevant.
When it comes to Glean, however, LLMs are provided the additional context they need to clarify caveats and precautions. This additional information enables AI to empower workers with the additional information they need to pursue next steps, or better understand why information they’re receiving may be incomplete.
The better way forward
If you’re looking to stay ahead of the curve by harnessing the potential of generative AI now and today, Glean is the best way to do it. Glean is always permissions aware, relevant and personalized, fresh and current, as well as universally applicable with your most used applications.
Supercharge your team’s productivity with a generative AI solution that’s truly enterprise-ready. Sign up for a demo today!


