




Work AI for all.
Give every employee an AI Assistant and Agents that put your company’s knowledge to work.



























%203.svg)
























September 25th • 9:30 AM PT
Let's get personal.
See how AI really gets to work. Tune in and discover what's possible.


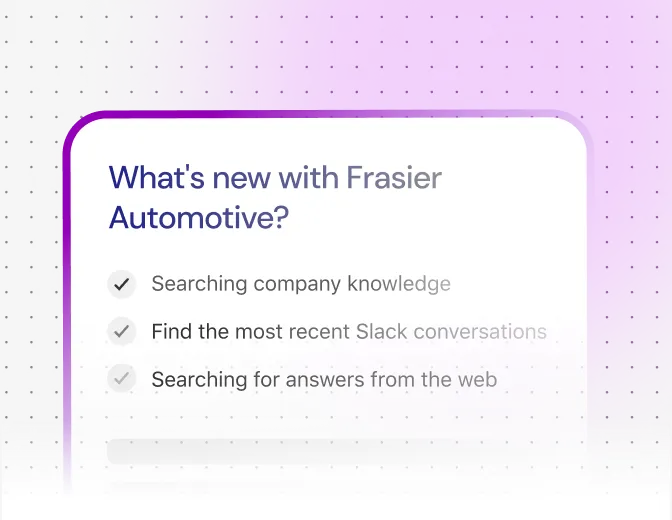
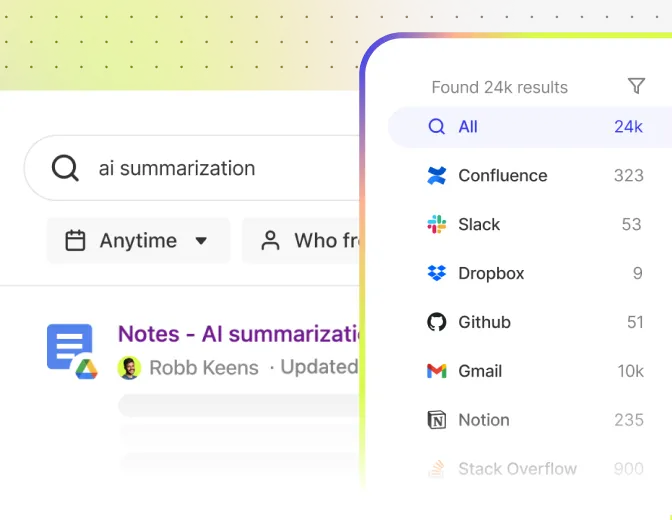
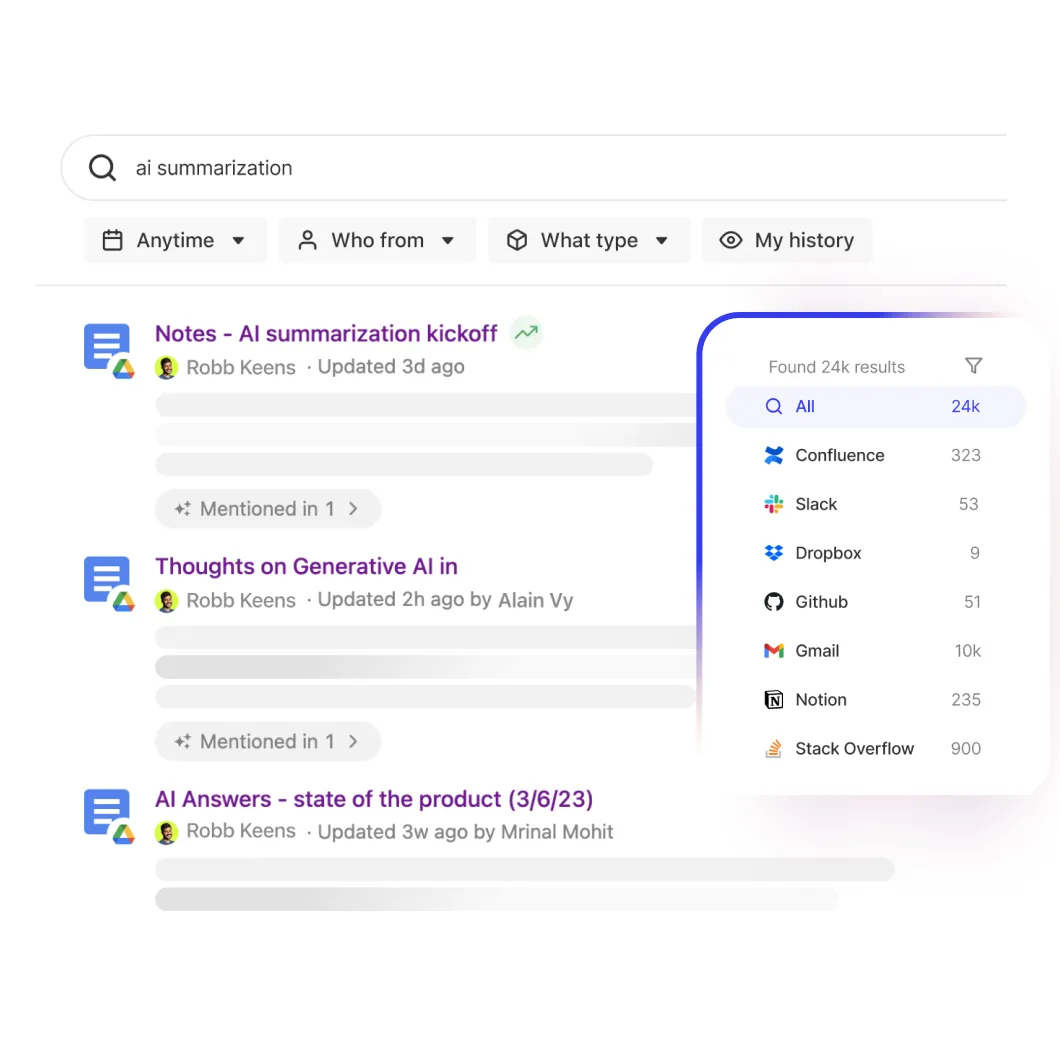
Reimagine your everyday work with AI.
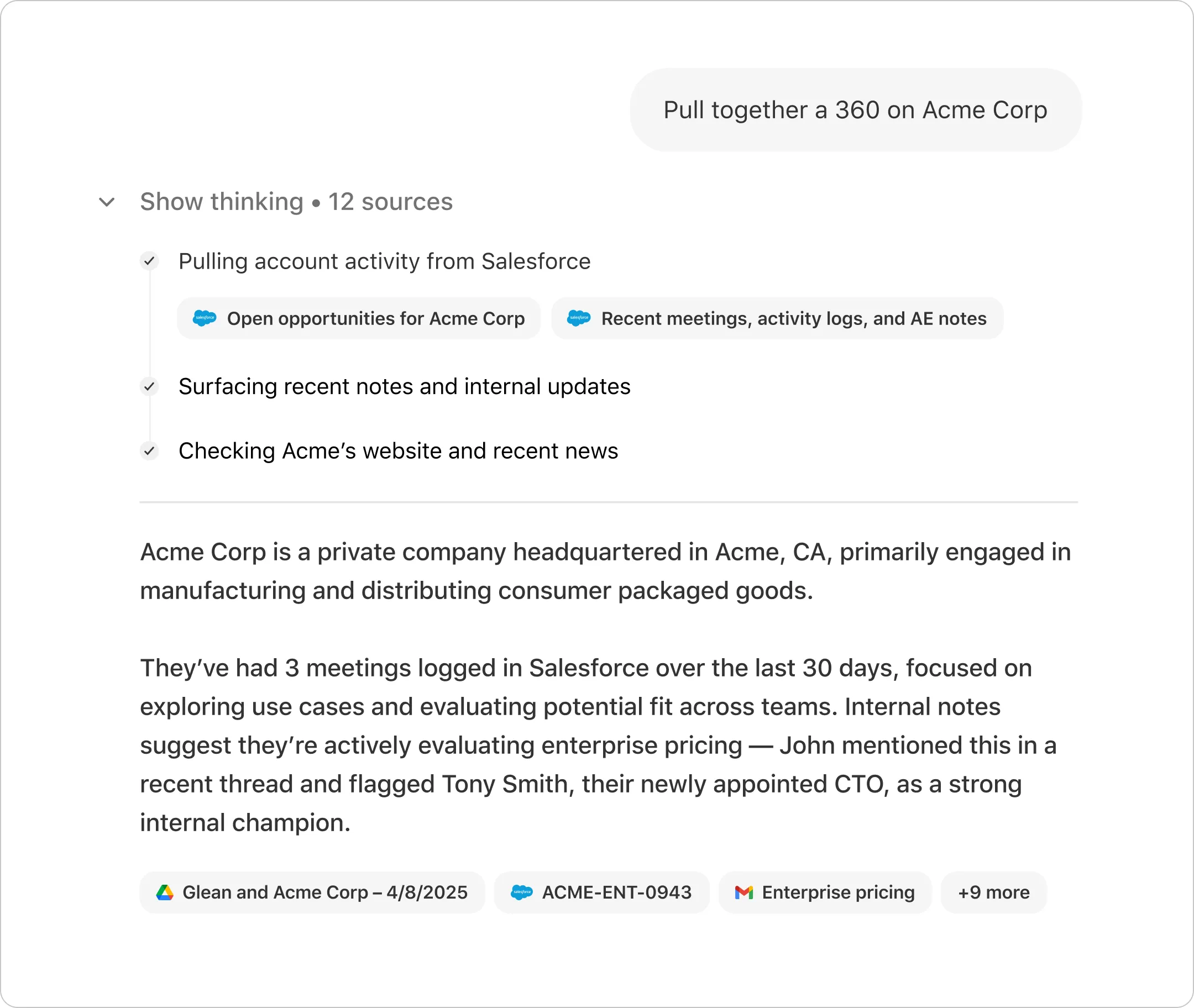
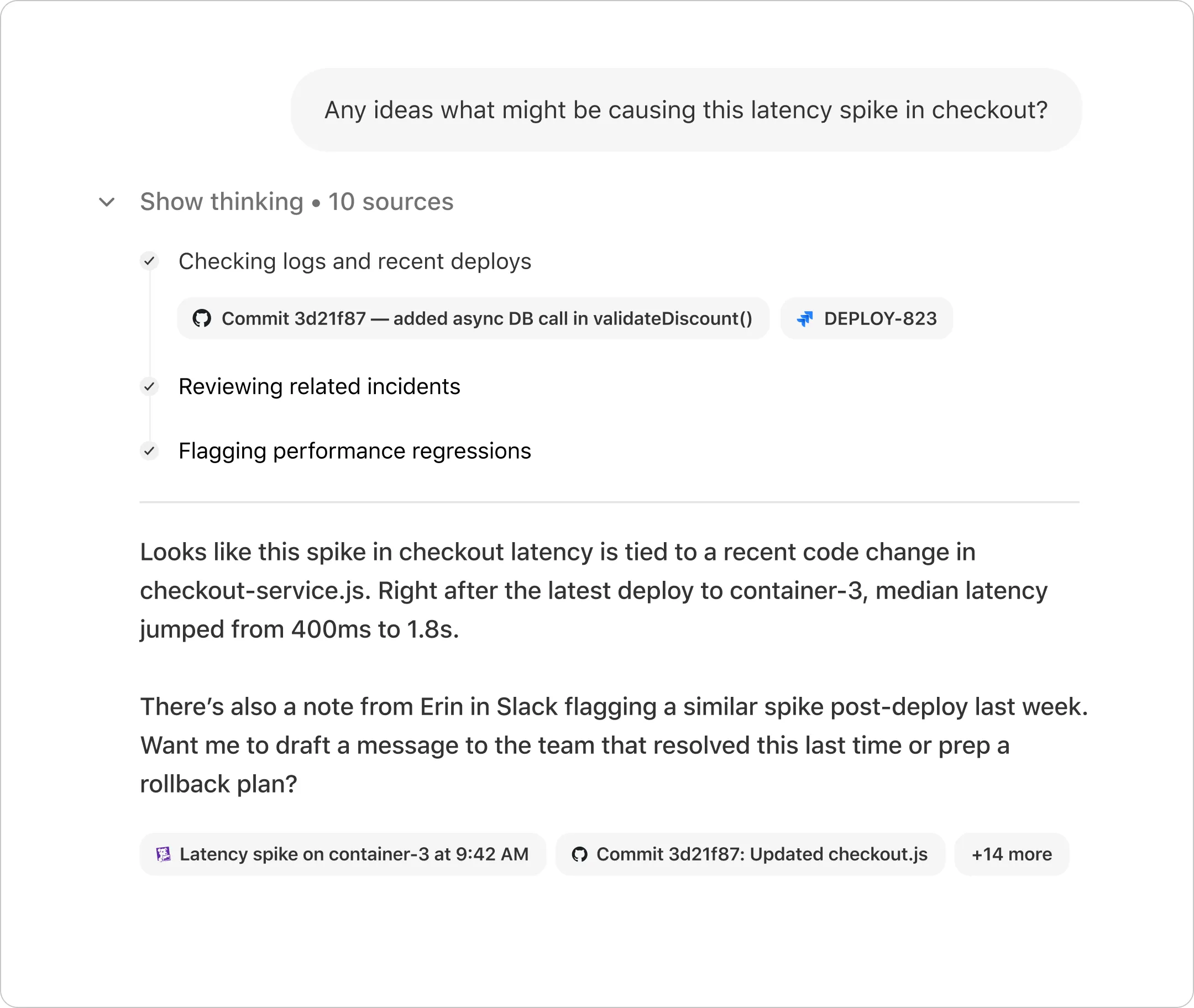
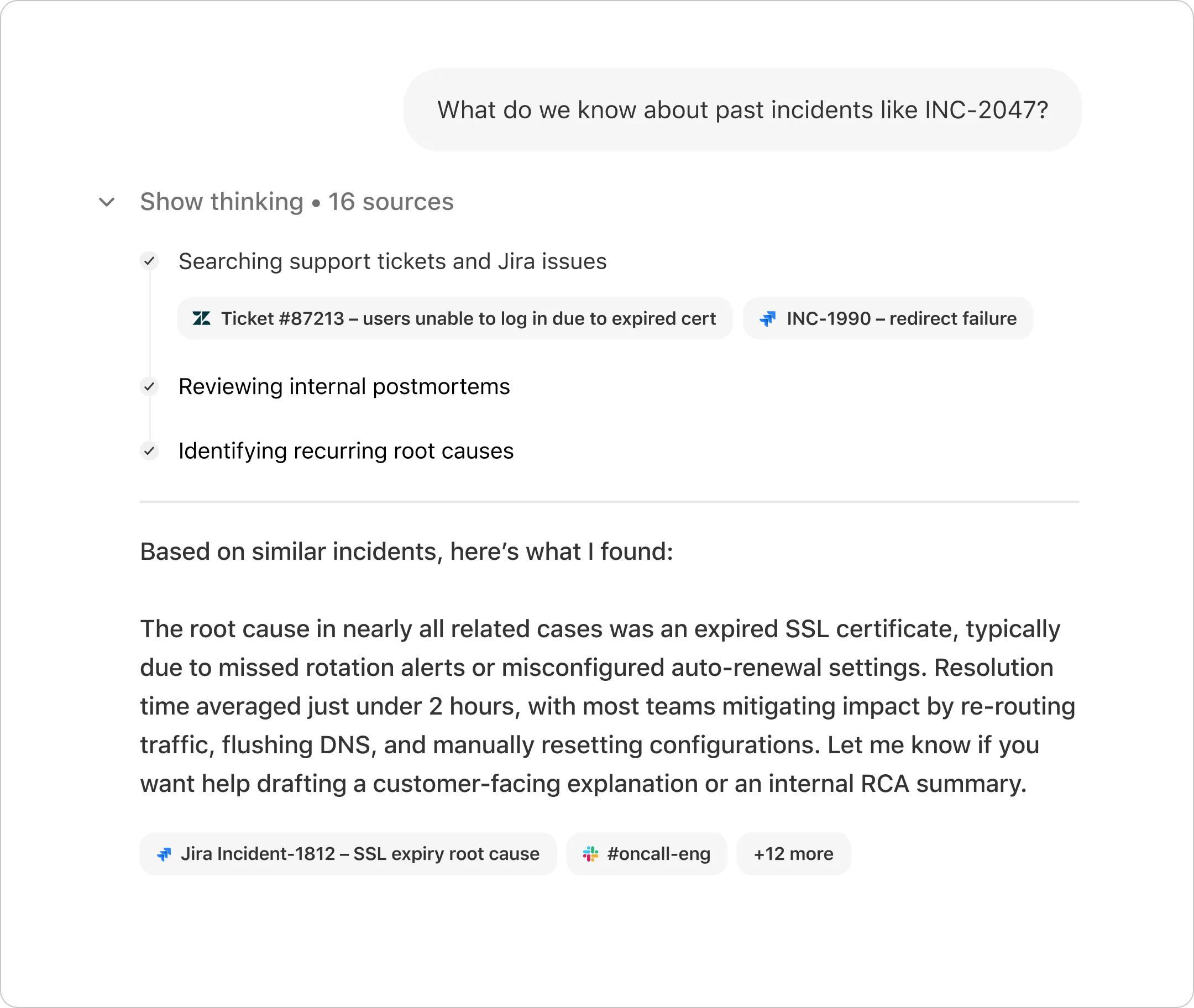
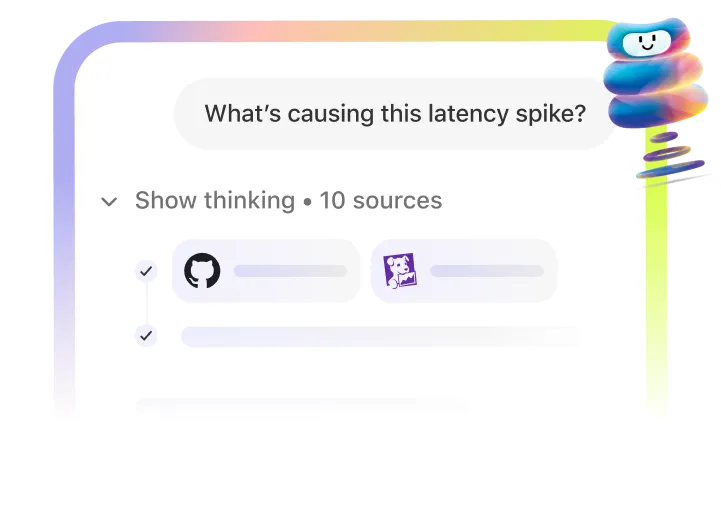
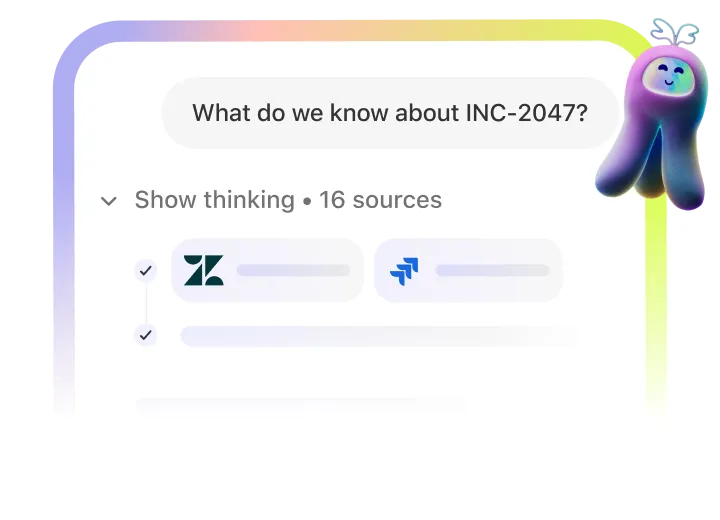
Find & understand

Create & summarize

Automate
One centralized platform for quickly and securely deploying AI in the enterprise.










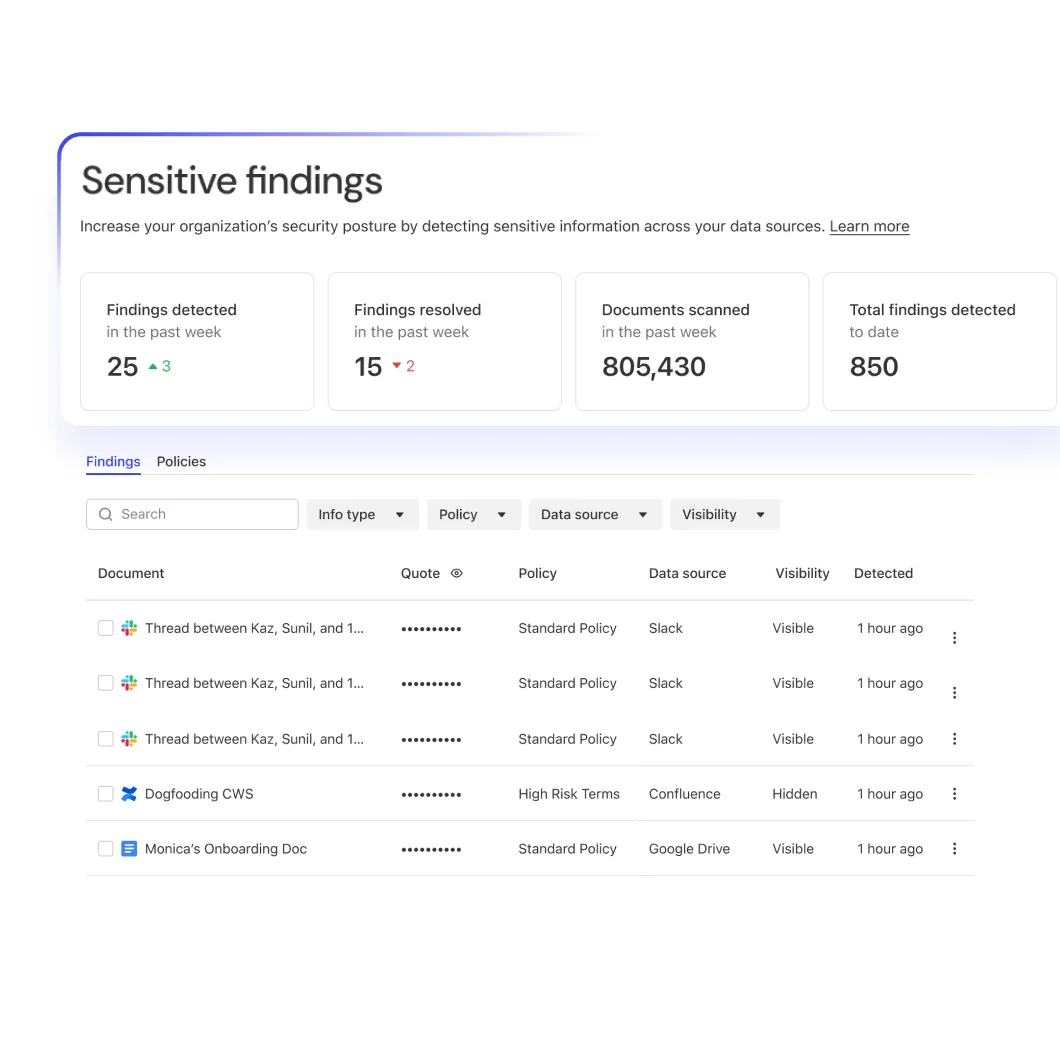
Platform extensibility
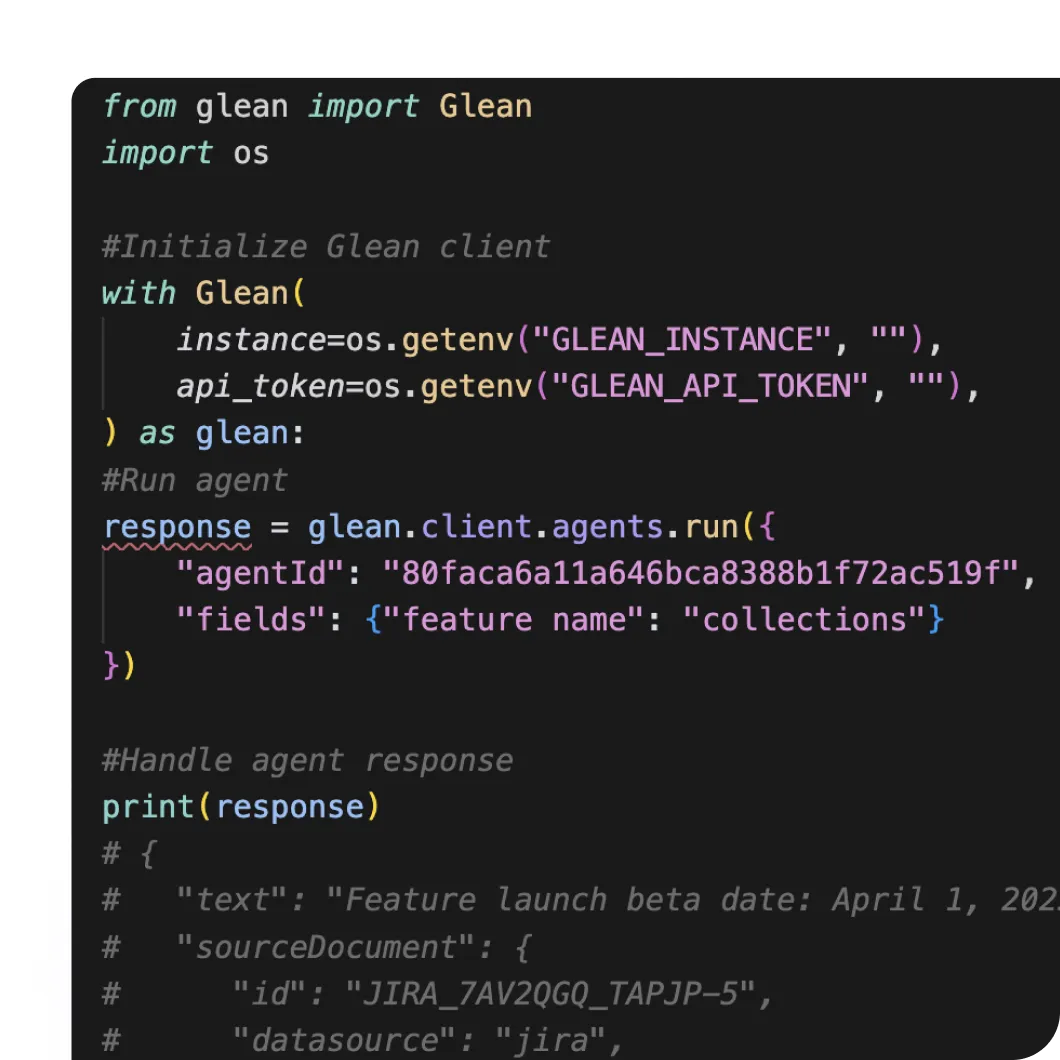
Extend Glean to any application with APIs, SDKs and custom plugins.
Glean saves up to 10 hours per user/year
See what our customers say







Glean helps you get work done, rather than just find information. The moment we launched Glean, there was so much positivity.
Tadeu Faedrick
Senior Engineer Manager



We built 'askT' as an employee concierge for all our employees in Germany. AskT combines the world knowledge of a LLM with thousands of knowledge bases — from finance, HR, and legal — all in one tool.
Jonathan Abrahamson
Chief Product & Digital Officer


Calibrations, email, presentations, content creation, etc., have gotten so much easier. I've seen stats that say Glean saves people 2-3 hours of time a week, but I know it's saving me a lot more time than that, and if you're not using Glean today, you really should be.
Steve Januario
VP of Technology


In my previous roles, I looked at and tried out tools that said they could handle enterprise search, both on-prem and Saas-based, but nothing worked. So, I was skeptical at first. However, Glean quickly proved that my skepticism was invalid.
Casey Carlton
Director of IT & Business Tech



It seems every SaaS platform has added some kind of generative feature, but they only have a single window of context. Glean brings the same thoughtful approach they brought to search to enterprise Al.
Manu Narayan
VP of IT, Data & Business Operations
Glean helps you get work done, rather than just find information. The moment we launched Glean, there was so much positivity.
Tadeu Faedrick
Senior Engineer Manager
We built 'askT' as an employee concierge for all our employees in Germany. AskT combines the world knowledge of a LLM with thousands of knowledge bases — from finance, HR, and legal — all in one tool.
Jonathan Abrahamson
Chief Product & Digital Officer
Calibrations, email, presentations, content creation, etc., have gotten so much easier. I've seen stats that say Glean saves people 2-3 hours of time a week, but I know it's saving me a lot more time than that, and if you're not using Glean today, you really should be.
Steve Januario
VP of Technology
In my previous roles, I looked at and tried out tools that said they could handle enterprise search, both on-prem and Saas-based, but nothing worked. So, I was skeptical at first. However, Glean quickly proved that my skepticism was invalid.
Casey Carlton
Director of IT & Business Tech
It seems every SaaS platform has added some kind of generative feature, but they only have a single window of context. Glean brings the same thoughtful approach they brought to search to enterprise Al.
Manu Narayan
VP of IT, Data & Business Operations
Glean helps you get work done, rather than just find information. The moment we launched Glean, there was so much positivity.
Tadeu Faedrick
Senior Engineer Manager
We built 'askT' as an employee concierge for all our employees in Germany. AskT combines the world knowledge of a LLM with thousands of knowledge bases — from finance, HR, and legal — all in one tool.
Jonathan Abrahamson
Chief Product & Digital Officer
Calibrations, email, presentations, content creation, etc., have gotten so much easier. I've seen stats that say Glean saves people 2-3 hours of time a week, but I know it's saving me a lot more time than that, and if you're not using Glean today, you really should be.
Steve Januario
VP of Technology
In my previous roles, I looked at and tried out tools that said they could handle enterprise search, both on-prem and Saas-based, but nothing worked. So, I was skeptical at first. However, Glean quickly proved that my skepticism was invalid.
Casey Carlton
Director of IT & Business Tech
It seems every SaaS platform has added some kind of generative feature, but they only have a single window of context. Glean brings the same thoughtful approach they brought to search to enterprise Al.
Manu Narayan
VP of IT, Data & Business Operations




Analyst Recognition

Glean Recognized as #1 Applied AI, Top 6 Globally
Named to Fast Company’s 2025 World’s Most Innovative Companies for enterprise AI leadership and innovation.

eMQ for GenAI
(AI Knowledge Management Apps / General Productivity)
Named as an "Emerging Leader" in the Emerging Market Quadrant.

Cool Vendors in Digital Workplace Apps
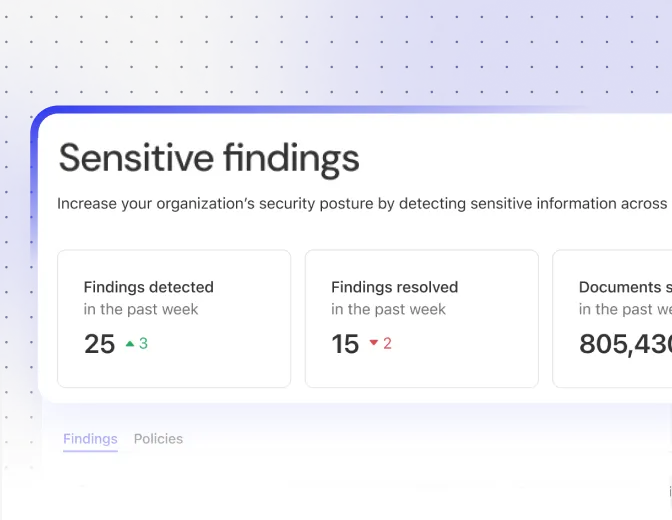
Agents must access, understand, and analyze your personal and enterprise data to do work
Work AI that works.
Get a demo


